Agenta
Agenta is an open-source LLMOps platform for building reliable AI apps. Manage prompts, run evaluations, and debug traces with your team.
About
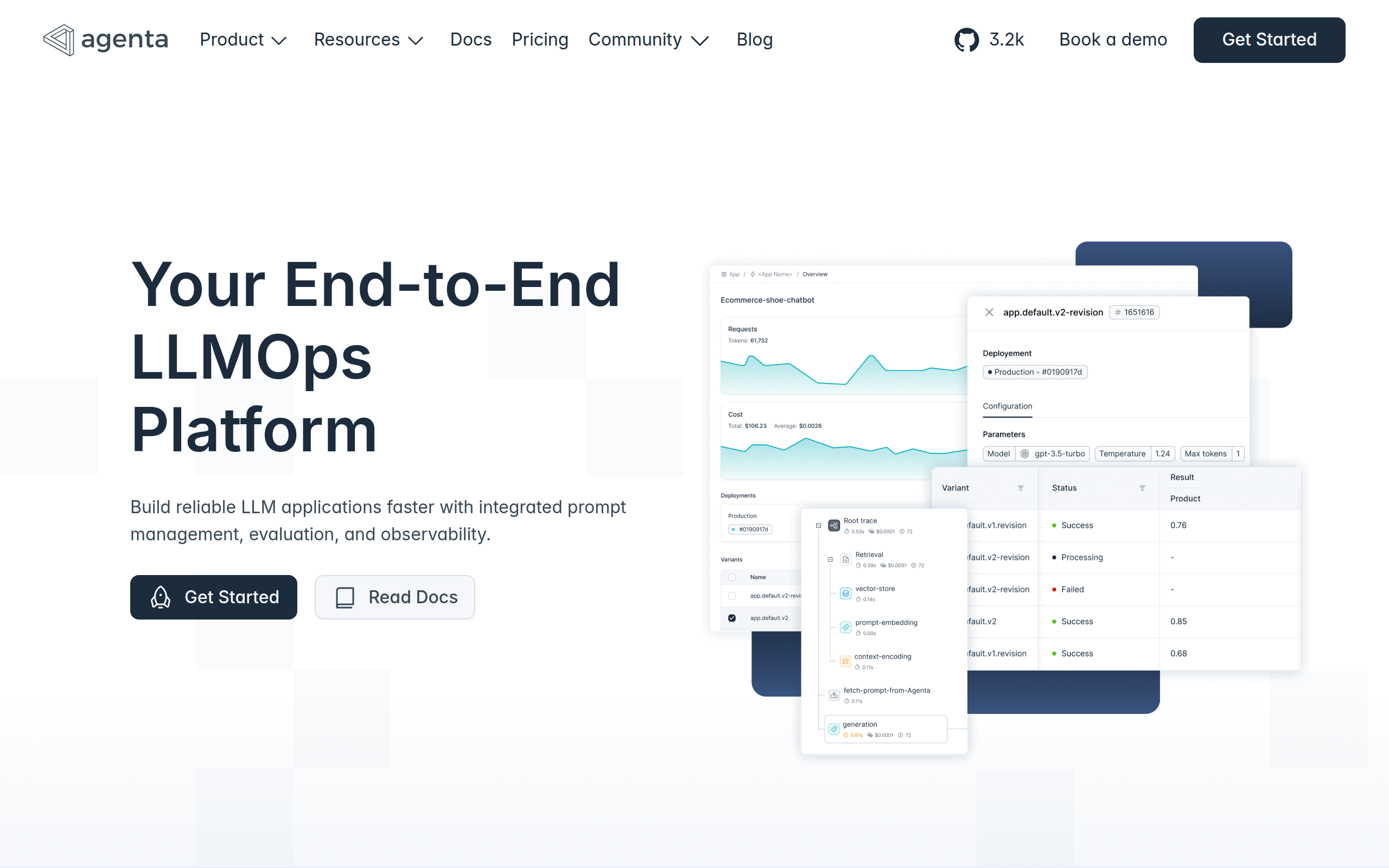
Agenta is an open-source LLMOps platform that helps AI teams build and ship reliable LLM applications. Developers and subject matter experts work together to experiment with prompts, run evaluations, and debug production issues. The platform addresses a common problem: LLMs are unpredictable, and most teams lack the right processes. Prompts get scattered across tools. Teams work in silos and deploy without validation. When things break, debugging feels like guesswork. Agenta centralizes your LLM development workflow: Experiment: Compare prompts and models side by side. Track version history and debug with real production data. Evaluate: Replace guesswork with automated evaluations. Integrate LLM-as-a-judge, built-in evaluators, or your own code. Observe: Trace every request to find failure points. Turn any trace into a test with one click. Monitor production with live evaluations.
Key Features
Centralized Prompt Management
Store, version, and organize prompts in a single place with full change history so teams can iterate safely and avoid scattered prompt copies across tools.
Unified Playground & Model Comparison
Compare prompts and multiple models side-by-side, run experiments on real production data, and keep track of outcomes to choose the best model/configuration.
Automated & Custom Evaluations
Run automated evaluation pipelines using built-in evaluators, LLM-as-a-judge, or your custom code to validate changes and quantify performance before deployment.
Observability & Trace-Based Debugging
Trace every request end-to-end, annotate failure points, convert any trace to a test with one click, and monitor production with live evaluations to detect regressions.
Collaboration Workflow for Cross-Functional Teams
Bring product managers, developers, and domain experts together with role-appropriate UIs for safe prompt editing, annotation, and human evaluation.
How to Use Agenta
1) Install or sign up and connect your LLM providers (self-host or API keys). 2) Import or create prompts and set up the unified playground to run and compare prompts against models. 3) Create automated evaluations (use built-in evaluators, LLM-as-a-judge, or upload custom evaluators) and run them on test sets. 4) Enable tracing and monitoring for production traffic, annotate traces, turn failing traces into tests, and iterate until performance is validated.